طراحیشده برای هوش مصنوعی و رایانش با کارایی بالا (HPC)
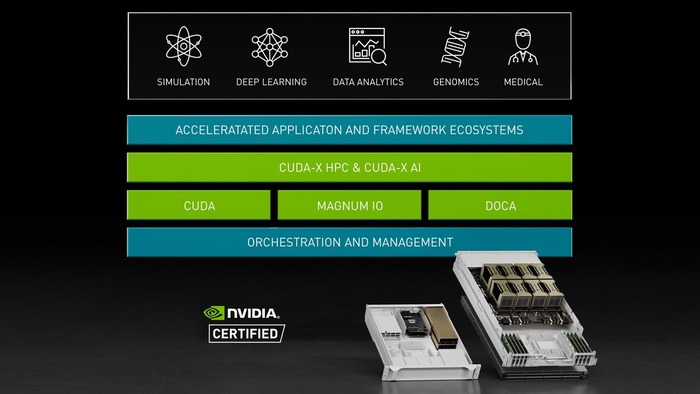
NVIDIA HGX بهعنوان یکی از پیشرفتهترین پلتفرمهای محاسباتی در جهان، برای پردازشهای پیچیده هوش مصنوعی و محاسبات با کارایی بالا (HPC) طراحی شده است. از تجزیه و تحلیل دادههای عظیم گرفته تا شبیهسازیهای پیچیده، این پلتفرم با ترکیب چندین پردازنده گرافیکی (GPU) و اتصالات فوقسریع، به شما کمک میکند تا چالشهای سنگین محاسباتی را به سرعت و کارآمد حل کنید.
با استفاده از پردازندههای گرافیکی قدرتمند NVIDIA، فناوری NVLink و شبکه اختصاصی انویدیا، پلتفرم HGX بهترین عملکرد را در اجرای برنامهها و تحلیل دادهها ارائه میدهد. همچنین مجموعه کاملی از نرمافزارهای بهینهسازی شده برای هوش مصنوعی و HPC در این پلتفرم موجود است.
شتابدهنده پیشرفته برای رایانش هوش مصنوعی
HGX B200 و HGX B100 با استفاده از پردازندههای NVIDIA Blackwell Tensor Core و اتصالات پرسرعت، مراکز داده را به سطح جدیدی از رایانش پیشرفته هدایت میکنند. این پلتفرمها تا 15 برابر عملکرد بهتری در استنتاج نسبت به نسلهای قبلی دارند و برای بارهای کاری سنگین هوش مصنوعی، تحلیل دادهها و HPC ایدهآل هستند.
این سیستمها از فناوریهای نوین NVIDIA Quantum-2 InfiniBand و Spectrum™-X Ethernet بهره میبرند که سرعتی تا 400 گیگابیت بر ثانیه ارائه میدهند. همچنین، استفاده از واحدهای پردازش داده (DPU) NVIDIA BlueField-3 امکان ایجاد شبکههای ابری با امنیت بالا و پردازش سریع در ابرهای هوش مصنوعی را فراهم میکند.
انعطافپذیری و کارایی در یادگیری عمیق
عملکرد پیشبینیشده ممکن است تغییر کند. زمان تأخیر توکن به توکن (TTL) برابر با ۵۰ میلیثانیه (ms) در زمان واقعی، زمان تأخیر اولین توکن (FTL) برابر با ۵ ثانیه، طول دنباله ورودی ۳۲,۷۶۸، طول دنباله خروجی ۱,۰۲۸ است. مقایسه عملکرد هر پردازنده گرافیکی در حالت خنککننده با هوا برای ۸ پردازنده گرافیکی NVIDIA HGX™ H100 هشتگانه در مقابل ۱ پردازنده گرافیکی HGX B200 هشتگانه.
پردازش همزمان برای نسل جدید مدلهای زبانی بزرگ
پلتفرم NVIDIA HGX برای یادگیری عمیق (Deep Learning) به گونهای طراحی شده است که حداکثر کارایی و انعطافپذیری را در اختیار کاربران قرار دهد. این پلتفرم به لطف معماری پیشرفته Blackwell Tensor Core و نوآوریهای TensorRT-LLM و Nemo Framework، پردازش مدلهای زبانی بزرگ (LLM) و Mixture-of-Experts (MoE) را تا 15 برابر سریعتر از نسل قبلی انجام میدهد.
این پیشرفتها به شما کمک میکنند تا مدلهای هوش مصنوعی پیچیده را با سرعت بیشتری آموزش داده و نتایج دقیقتر و سریعتری کسب کنید.
شبکهسازی پیشرفته با NVIDIA HGX
در مراکز داده مدرن، شبکهسازی نقشی کلیدی در ارتقای عملکرد برنامههای هوش مصنوعی ایفا میکند. پلتفرم HGX به همراه NVIDIA Quantum InfiniBand، بهترین عملکرد را در استفاده بهینه از منابع محاسباتی فراهم میکند.
برای مراکز داده ابری که از اترنت استفاده میکنند، NVIDIA HGX به کمک پلتفرم شبکهسازی NVIDIA Spectrum-X، بالاترین سطح عملکرد هوش مصنوعی را بر روی اترنت ارائه میدهد. ترکیب سوئیچهای NVIDIA Spectrum™-X و واحدهای پردازش داده BlueField-3، امکان اجرای هزاران کار هوش مصنوعی بهصورت همزمان را فراهم میآورد و با ایجاد جداسازی عملکردی و امنیتی پیشرفته، مناسب محیطهای ابری است.
یکی از نمونههای برجسته این فناوری، ابرکامپیوتر Cambridge-1 است که به عنوان یکی از قدرتمندترین ابررایانههای هوش مصنوعی در بریتانیا شناخته میشود. این ابرکامپیوتر، با استفاده از سرورهای قدرتمند و پلتفرم NVIDIA HGX و فناوریهای شبکهای پیشرفته، برای تسریع در تحقیقات پزشکی و سلامت طراحی شده است.
مشخصات فنی NVIDIA HGX
NVIDIA HGX در بردهای تکی با چهار یا هشت GPU مدل H200 یا H100، یا هشت GPU مدل Blackwell در دسترس است. این ترکیبهای قدرتمند از سختافزار و نرمافزار، پایه و اساس عملکرد بینظیر ابررایانههای هوش مصنوعی را فراهم میکنند.